PDF viewer text search speed comparison
Recently, I implemented a super fast search index into sioyek which accelerates normal search and also enabled regular expression search.
It is not yet released in a stable sioyek build, but if you want to try it out, there are experimental builds here.
It is not enabled by default (it slightly increases memory consumption, so I disabled it by default) but can be enabled by adding this to prefs_user.config file:
super_fast_search 1
In order to test it, I decided to find all instances of letter ‘a’ in a 730-page document. See the result in this video:
However, I didn’t think this benchmark was good enough for multiple reasons:
- Some very popular PDF viewers are missing. The reason is that many of them don’t report the number of matches (for example sumatra just jumps to the next match and firefox just finds the first 1000 matches). Therefore we could not compare those readers.
- Finding all instances of ‘a’ might not be a very useful search in practice
- Sioyek finds the results so fast that we can not get an accurate measure of its time
So I decided to find a harder PDF file and do another benchmark on that. Now the previous file already wasn’t that small (it was 730 pages), but I needed a significantly larger file, and I didn’t want to create a file myself because I wanted the result to be as authentic as possible. In my search of a big-ass book I came across this behemoth:

It’s 4100 pages of tightly packed, two-column, small-font text. And it is the perfect test subject for us.
But before doing the new tests, let’s repeat our old test (finding all instances of ‘a’) in this book, just to get a sense of how large it is. I tested it only with the viewers that found all the results (sioyek, zathura, mendeley, zoreto, chrome, and edge). Here are the results:
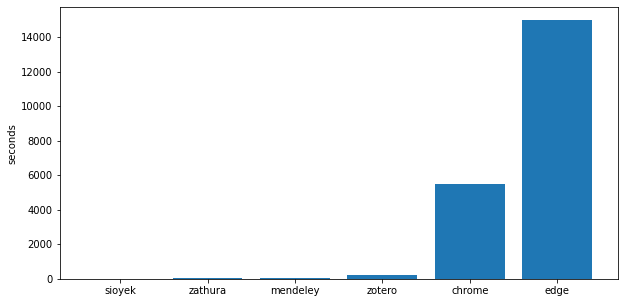
Well, that’s not really useful. Let’s remove chrome and edge which seem to be outliers, hopefully now it will be more informative:
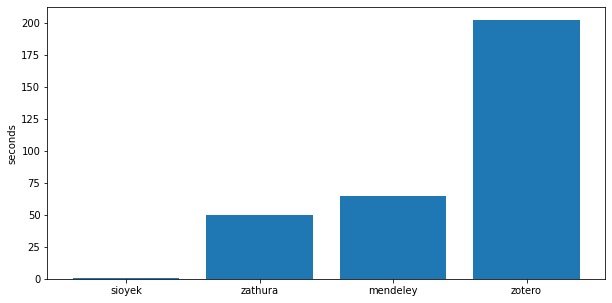
Fuck it. Here is the raw data:
| program | time (s) |
|---|---|
| sioyek | 0.9 |
| zathura | 50 |
| mendeley | 65 |
| zotero | 202 |
| chrome | 5500 |
| edge | 15000 |
Note that chrome and edge took so long that I terminated them after 10 minutes and extrapolated the final time based on the results found in ten minutes. Which is very generous because chrome was showing clear signs of non-linear behavior which means that the true time might be even larger than this.
Main benchmark
Okay now we get to the main benchmark. In order to reduce the variance and also effects of particular algorithms (for example some viewers search from the beginning, and so they perform better if the query is in the first pages, some other viewers start from current page, etc.) we used the following process:
- 10 pages in the document were chosen completely randomly
- A string was chosen from each page, such that this string does not appear on any other page of the document
- In order to test a viewer, we open the viewer on the first page of the document and search for the chosen strings, one by one, and we don’t change the pages (so we are on the page of ith result when starting the search for (i+1)th result)
- We report the average and the median of search times
Here are the results:
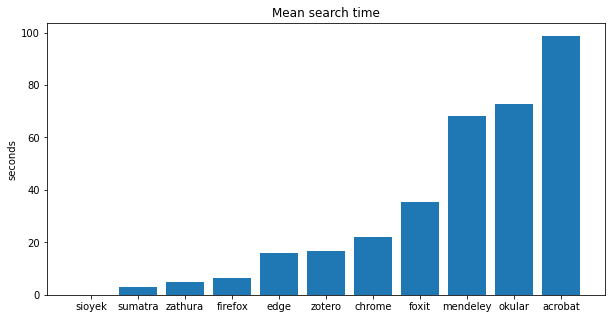
Again, let’s remove the large values:
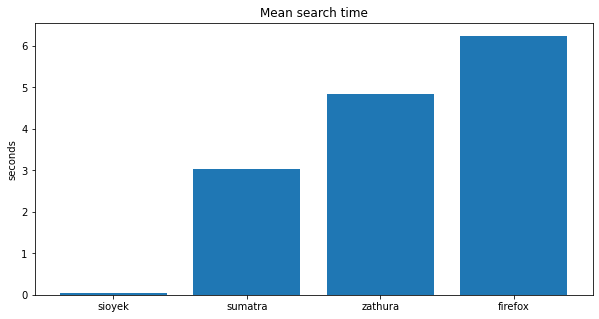
Sigh, here are the raw numbers:
| program | average time (s) |
|---|---|
| sioyek | 0.03 |
| sumatra | 3.0 |
| zathura | 4.8 |
| firefox | 6.2 |
| edge | 15.7 |
| zotero | 16.5 |
| chrome | 22.2 |
| foxit | 35.4 |
| mendeley | 68.1 |
| okular | 72.8 |
| acrobat | 98.7 |
Now I must admit, the reason sioyek is so fast is because it creates a search index when you open the document. In these tests I have waited until this search index is built (with the justification that the index-building is fast enough that by the time the user wants to do a search in the document it is done). Some other PDF viewers (namely, zathura, firefox and sumatra) seem to create indices to speed up searches too, however, instead of creating it when the document is opened, they create it the first time you perform a search, which causes the first search to take unusually long time but the subsequent searches are much faster. I don’t think this comparison is unfair, because it accurately reflects the time that the users have to wait for their search results (in fact, I think it is a little generous because 10 searches is probably above-average number of searches, and the fewer searches we have, the more pronounced the effect of first search indexing becomes). But to be completely fair, I also computed the median search time which is not affected by the indexing in the first search. Here are the results:
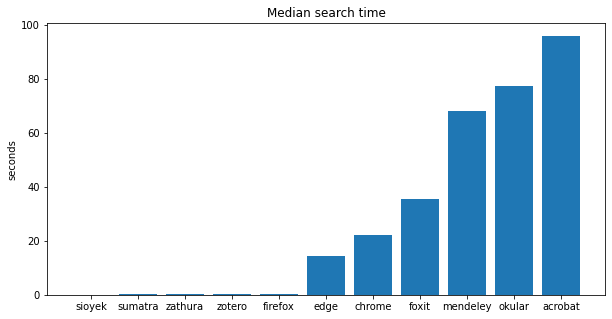
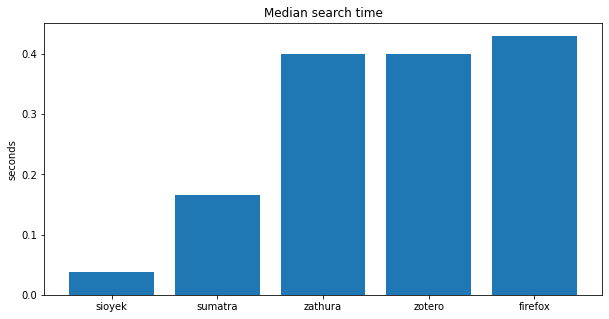
You can see there is a visible gap between the programs that do the indexing and those that don’t. Here is a comparison the programs that do the indexing:
Indexing Time
One more important factor for the programs that do the indexing is the time it takes to create the index. Here are the results:
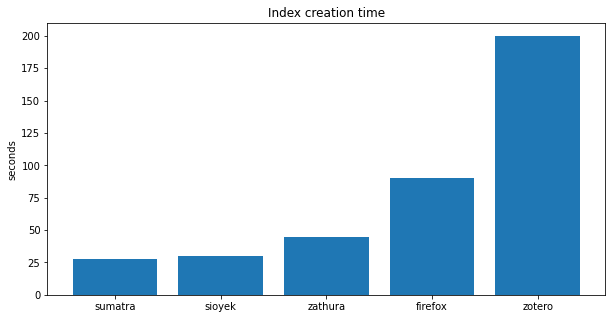
Finally sioyek has been dethroned, although it is very close (30 seconds vs 28 seconds). I think the reason is that we don’t just index the text of the document during the index procedure. We also try to find all the figures, references, equations, etc. which enables the smart jump feature.
How does the indexing work?
I wish I could tell you that I made some genius optimizations to make the search fast, however, the truth is that the index is extremely trivial: we just concatenate the text of all the pages, and also create some backward indices so that we can find the page and location of a match in the document given its location in the concatenated string. That’s it. In fact almost all the credits goes to the writers of c++’s standard library functions std::find and std::regex_search.
So after all, sioyek’s speed is not that impressive. What I would say is impressive though is how slow some programs manage to be. For example the average search time in acrobat, the program create by adobe, the multi-billion dollar company that created the PDF format and employs more than 25000 people is more than 3000 times slower than the average search time in sioyek. It is even more than 3 times slower than the time it takes sioyek to build the entire search index! Now that’s impressive.