Disclaimer: Most of this post was written Jun 20th, 2025, but some links and images were added later.
Today that I am typing these words is Friday, Jun 20th, 2025 though in all likelihood it is not the date that they will be published. Almost exactly a week ago Israel attacked Iran, igniting the 40-year old cold-war between the two nations. This is probably the most serious existential threat to the Islamic Republic since its inception in 1979. In trying times like these, the Islamic Republic shows that it truly believes in something, something that has always saved them in the direst situations and always protected them from the most formidable adversaries. Yes: I am, of course, talking about internet censorship.
To understand what the internet in Iran is like now, let me first paint you the picture of the internet in “normal” times: All non-state affiliated news networks are blocked. All blogger/wordpress weblogs are blocked. All messenger apps like telegram or whatsapp are blocked (whatsapp was briefly unblocked for a few months but it is blocked again now). Facebook, twitter, youtube, twitch, reddit, instagram, tiktok, feedly, discord are blocked.
What is not blocked you ask? Well most google services are not blocked (e.g. search, gmail, maps). Though our friends in silicon valley sure try to make us feel at home:
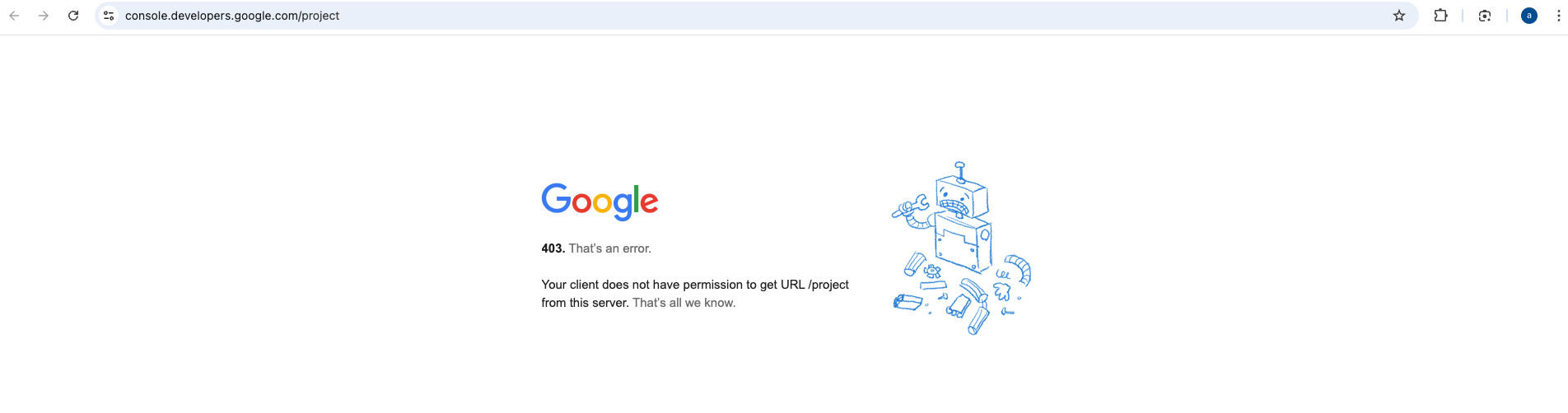
This is what you see when you try to enter google developer console with an Iranian IP address. It is not blocked from Iran’s side but it is unavailable due to sanctions (that’s all you know? I bet you know a little more than that!). Chatgpt? 403. Google AI Studio? 403. Most online videogames? 403. Android developer documentation (for fuck’s sake)? 403.
Now you might say such an internet is completely unusable. And you would be correct. That’s why 81% of Iranians use VPNs to access the free internet (and remember, this is a survey conducted by Iranian Parliament Research Center in a country where VPNs are technically illegal, so the actual number might be much higher than this).
So that was the internet in peace time. How does the internet look like in the war time where access to the information is most vital? Well, it appears that the regime has completely shut off Iran from the rest of the world. No incoming or outgoing traffic can cross the borders.
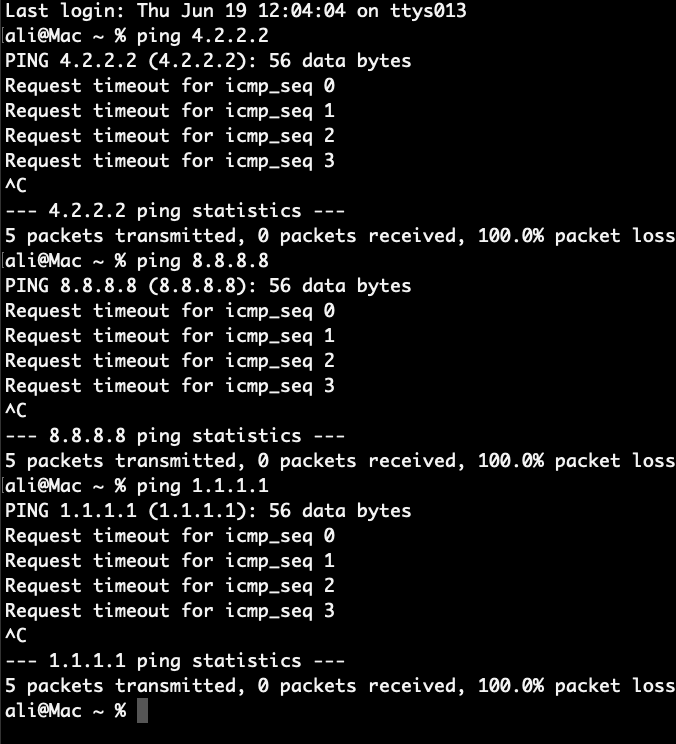
Their excuse for doing so are the following:
- There were some attacks on some banks
- One of the largest cryptocurrency exchanges in Iran was hacked and more than 100 million dollars was stolen
- There were claims that Israeli drones were using Iranian SIM card internet to operate
I am not going to comment on the validity of these arguments, they may be true. But remember that the internet also was shut down during the 2019 and 2022 protests and there were no cyberattacks then.
There is one external website that for some reason is not blocked though: google. It seems like the ip address 216.239.38.120 which belongs to google is specifically whitelisted.
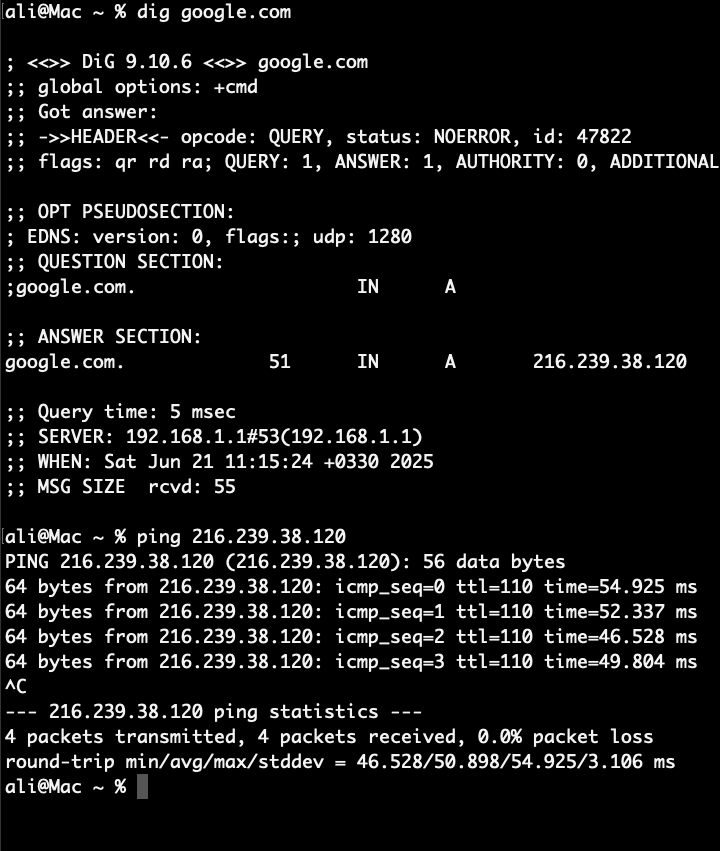
So I can for example search for recent news about iran, but I can only view the title and the short content preview in the google search results, I can not open the articles.
Since I can’t get any real work done (even internal ssh connections are blocked now!) I decided to do some work on voil (my vscode extension which is similar to oil.nvim) which I have been putting off for a while, it is a fun way to distract myself and stop stressing about the news. The problem is, I am not really experienced when it comes to vscode extensions, which means a lot of documentation lookups is necessary. And you might guess what the problem is: while I can search for the documentation, I have no way of actually reading the contents … or do I? This is where the AI preview feature comes in, while this feature has been hated on a lot since its introduction, I can’t deny that it did really help keep my sanity during this time.
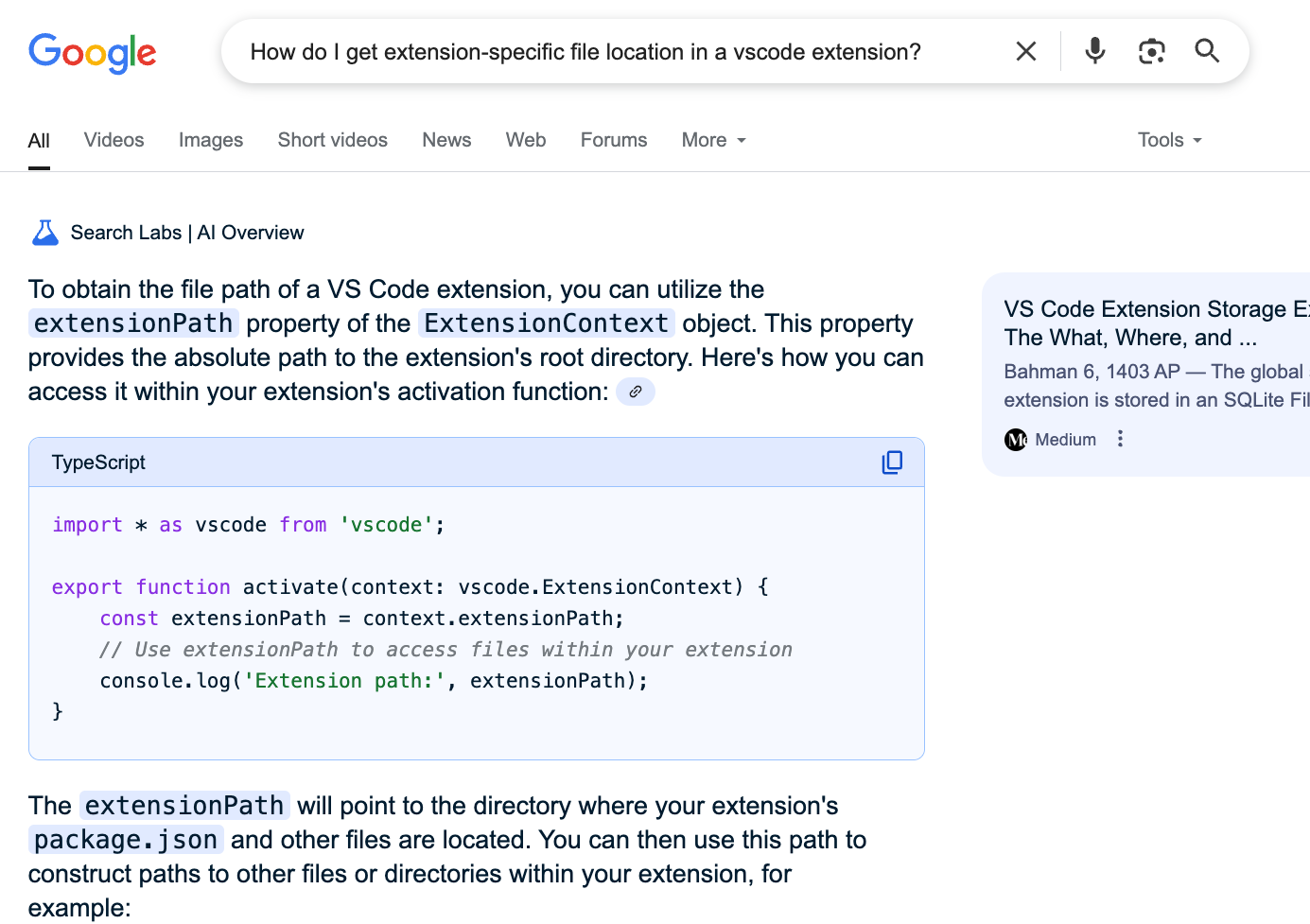
Unfortunately there is no way to force an AI preview answer (and it is not even deterministic, for the same query sometimes there is an ai answer and sometimes there isn’t). But forming the query as a question significantly increases the probability of an answer though of course it is not 100%. Unfortunately I found it to be less useful for reading news, but it was very effective for reading the documentation.
Anyway, while it is fashionable these days to hate on everything AI-related, I thought it was salient to mention this small way that AI managed to help me. Of course google used to have a cache feature where you could view the cached version of websites. It was a highly useful feature, which, of course, means it was removed a while back. If that feature was still available, all these shenanigans would have been unnecessary, though I suspect if that was the case then the google IP would not have been whitelisted in the first place. Also it would have been very useful to have a way to force/control the AI preview.
]]>